

# ETL
The "hello, world!" of the data engineering world
ETL ("extract, transform, load") is a basic data workflow, but can be surprisingly complicated to set up in most data engineering frameworks.
Some tools don't have an easy way to pass data between tasks, resulting in companies maintaining internal representations of all possible combinations of sources and sinks (S3_to_Redshift; S3_to_S3; Redshift_to_S3; Postgres_to_Redshift; Postgres_to_S3, etc.). Other frameworks have flexible sources and sinks, but lack the ability to write totally customizable transformations.
Prefect makes ETL easy.
# E, T, and L
Let's get started by defining three functions that will serve as our extract, transform, and load tasks. You can put anything you want in these functions -- for illustration, we're just going to work with a simple array.
All we have to do in order to invoke Prefect is apply the @task decorator to our functions.
Passing data between tasks
Don't worry about passing large data objects between tasks. As long as it fits in memory, Prefect can handle it with no special settings. If it doesn't, there are ways to distribute the operation across a cluster.
from prefect import task
@task
def extract():
"""Get a list of data"""
return [1, 2, 3]
@task
def transform(data):
"""Multiply the input by 10"""
return [i * 10 for i in data]
@task
def load(data):
"""Print the data to indicate it was received"""
print("Here's your data: {}".format(data))
# The Flow
Now that we have our tasks, we create a Flow and call the tasks as if they were functions. In the background, Prefect is generating a computational graph that tracks all dependencies between our tasks.
Deferred execution
It may look like we're calling our ETL functions, but nothing is actually being executed here. In Prefect, calling a task is a convenient way to tell the framework how it relates to other tasks; Prefect uses that information to build the computational graph. Nothing actually happens until you call flow.run().
from prefect import Flow
with Flow('ETL') as flow:
e = extract()
t = transform(e)
l = load(t)
flow.run() # prints "Here's your data: [10, 20, 30]"
If we call flow.visualize(), Prefect will draw the computational graph:
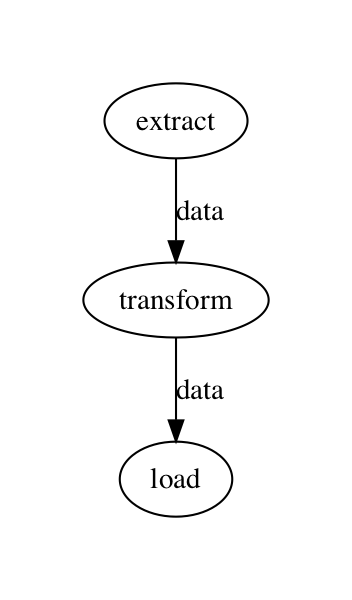
# An Imperative Flow
We love Prefect's functional API, but some users might prefer a more explicit approach. Fortunately, Prefect can be operated through an imperative API as well.
Here's an identical Flow, built with the imperative API:
from prefect import Flow
flow = Flow('ETL')
flow.set_dependencies(transform, keyword_tasks=dict(data=extract))
flow.set_dependencies(load, keyword_tasks=dict(data=transform))
flow.run() # prints "Here's your data: [10, 20, 30]"
Mix-and-match
Prefect's functional API and imperative API can be utilized at any time, even for a single line in a script that uses the other style for everything else. One of the only key differences is that the functional API requires code to be run in an active Flow context.