

# Using Results
Let's take a look at using results to persist and track task output. As introduced in the concept documentation for "Results", Prefect tasks associate their return value with a Result object attached to a task's State. If you configure the Result object for a task and enable checkpointing, the pipeline will also persist results to storage as a pickle into one of the supported storage backends.
Why would you persist the output of your tasks? The most common situation is to enable retrying from failure of a task for users that use a state database, such as Prefect Core's server or Prefect Cloud. By persisting the output of a task somewhere besides in-memory, a state database that knows the persisted location of a task's output can restart from where it left off. In the same vein, using a persistent cache to prevent reruns of expensive or slow tasks outside of a single Python interpreter is only possible when the return value of tasks are persisted somewhere outside of memory. Another common situation is to allow for inspection of intermediary data when debugging flows (including—maybe especially—production ones). By checkpointing data during different data transformation Tasks, runtime data bugs can be tracked down by analyzing the checkpoints sequentially.
# Setting up to handle results
Checkpointing must be enabled for the pipeline to write a result. You must enable in two places: globally for the Prefect installation, and at the task level by providing a Result subclass to tasks either through its flow initialization or as a task-level override. Depending on which result subclass you configure, you may also need to ensure your authentication credentials are set up properly. For users of Prefect Core's server or Prefect Cloud, some of this is handled by default.
For Core-only users, you must:
- Opt-in to checkpointing globally by setting the
prefect.config.flows.checkpointingto "True" via your preferred Prefect configuration - Specify the result your tasks will use for at least one level of specificity (flow-level or task-level)
For Prefect Core server or Prefect Cloud users:
- Checkpointing will automatically be turned on; you can disable it by passing
checkpoint=Falseto each task you want to turn it off for - A result subclass that matches the storage backend of your
prefect.config.flows.storagesetting will automatically be applied to all tasks, if available; notably this is not yet supported for Docker Storage - You can override the automatic result subclass at the global level, flow level, or task level
# Setting result at the flow level
export PREFECT__FLOWS__CHECKPOINTING=true
# flow.py
from prefect.engine.results import LocalResult
@task
def add(x, y=1):
return x + y
# send the configuration to the Flow object
with Flow("my handled flow!", result=LocalResult()):
first_result = add(1, y=2)
second_result = add(x=first_result, y=100)
# Setting result at the task level
export PREFECT__FLOWS__CHECKPOINTING=true
# flow.py
from prefect.engine.results import LocalResult, PrefectResult
# configure on the task decorator
@task(result=PrefectResult())
def add(x, y=1):
return x + y
class AddTask(Task):
def run(self, x, y):
return x + y
# or when instantiating a Task object
a = AddTask(result=LocalResult(dir="/Users/prefect/results"))
with Flow("my handled flow!"):
first_result = add(1, y=2)
second_result = add(x=first_result, y=100)
# Choosing your result subclass
In the above examples, we only used the LocalResult class. This is one of several result subclasses that integrate with different storage backends; the full list is in the API docs for prefect.engine.results and more details on this interface is described in the concept "Results" documentation.
We can write our own result subclasses as long as they extend the Result interface, or we can pick an existing implementation from Prefect Core that utilizes a storage backend we like; for example, I will use prefect.engine.results.GCSResult so that my data will be persisted in Google Cloud Storage.
# Example: Running a flow with GCSResult
Since the GCSResult object must be instantiated with some initialization arguments, we utilize a flow-level override to pass in the Python object after configuring it:
# flow.py
from prefect.engine.results import GCSResult
gcs_result = GCSResult(bucket='prefect_results')
with Flow("my handled flow!", result=gcs_result):
...
Make sure your Prefect installation can authenticate to Google's Cloud API. As long as the host of my Prefect installation can authenticate to this GCS bucket, each task's return value will be serialized into its own file in this GCS bucket.
After running my flow, I can see that my task states know the key name of their individual result storage in Result.location when I inspect them in-memory:
>>> state = flow.run()
>>> state.result[first_result]._result.location
'2020/2/24/21120e41-339f-4f7d-a209-82fb3b1b5507.prefect_result'
>>> state.result[second_result]._result.safe_value
'2020/2/24/133eaf17-ab77-4468-afdf-734b6540dde0.prefect_result'
Using gsutil, I can see that those keys exist in the GCS bucket I configured my result to submit data to:
$ gsutil ls -r gs://prefect_results
gs://prefect_results/2020/:
gs://prefect_results/2020/2/:
gs://prefect_results/2020/2/24/:
gs://prefect_results/2020/2/24/59082506-9217-436f-9d69-9ff569b20b7a.prefect_result
gs://prefect_results/2020/2/24/a07dd6c1-837d-4925-be46-3b525be57779.prefect_result
If you are using Prefect Cloud, you can see that this metadata from the "safe value" is also stored and exposed in the UI:
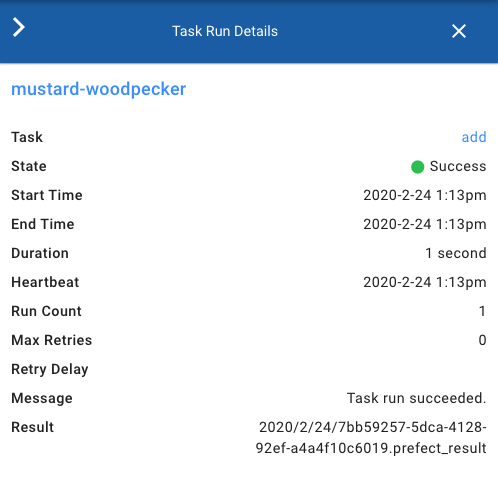
# Providing a task's location directly
In the above example, we configured our GCSResult's bucket, but let the Prefect pipeline autogenerate the filename itself as a UUID. If you want more control over the name of the location the task writes to, you can pass a string to the result's location kwarg, like so:
# flow.py
from prefect.engine.results import GCSResult
gcs_result = GCSResult(bucket='prefect_results', location='my_task.txt')
@task(result=gcs_result)
def my_task():
# ...
Now my flow will always store this task's data at gs://prefect_results/my_task.txt directly.
# Templating a task's location
You can also provide a templatable string to a result subclass' location attribute. You can include in the template string anything that is in prefect.context, including any custom context you set. Note that standard Python string formatting rules apply, so for example you can provide custom date formatters (e.g., "{date:%Y-%d}") to your locations and targets.
For example, we can achieve the same thing as our prior example but using the fact that prefect.context.task_name will resolve to the task's function name at runtime:
# flow.py
from prefect.engine.results import GCSResult
gcs_result = GCSResult(bucket='prefect_results', location='{task_name}.txt')
@task(result=gcs_result)
def my_task():
# ...
This will also store my task's data at gs://prefect_results/my_task.txt, but it interpolated the task's name from context instead of requiring it to be hardcoded in the result initialization.
This can become quite powerful and allow you to reuse the same result instance to configure multiple tasks to be persisted, based on distinguishing contextual information for each task. It becomes even easier if we configure the whole flow at once by providing a result that has a location attribute that, when formatted, will be disambiguous for each task. For example, the following flow will persist the return value for my_task and my_second_task in separate GCS keys named after each task, with limited code configuration.
# flow.py
from prefect.engine.results import GCSResult
gcs_result = GCSResult(bucket='prefect_results', location='{task_name}.txt')
@task
def my_task():
# ...
@task
def my_second_task():
# ...
with Flow("my handled flow!", result=gcs_result):
my_task()
my_second_task()
$ gsutil ls -r gs://prefect_results
gs://prefect_results/my_task.txt
gs://prefect_results/my_second_task.txt
# Specifying a location for mapped or looped tasks
Mapped or looped tasks require special consideration when it comes to their result location, as they may run many times and each of their results can be stored separately.
# Mapping
When configuring results for a mapped pipeline, if you choose to configure the location it is highly recommended that you include {task_run_id}, {map_index}, or a fine-grained timestamp to your location template to disambiguate the data returned by each dynamically spawned child task.
# Looping
Assuming you have configured your Flow to run with persistence, each iteration of your looped task will write to your configured Result location. When using Prefect defaults this means that each iteration will produce a new file with a different timestamp and UUID.
If instead you provide a custom location, you'll need to decide whether you want each loop iteration to result in a new filename or whether you are comfortable with each iteration overwriting the previous one. If you prefer to keep the results separate, note that Prefect provides task_loop_count in Prefect context so the simplest solution is to use {task_loop_count} in your templated location.
# Running a flow with PrefectResult
A unique case is the PrefectResult, as it serializes its PrefectResult.value as its Result.location. This is only useful for small data loads and for data that Cloud users are comfortable sharing with the Cloud database. When used effectively, they can provide efficient inspection of data output in the UI. For this reason, all Parameter type Tasks use this as their result subclass.
Let's see this with an example. The same flow that adds numbers together will instead be configured with the PrefectResult:
# flow.py
from prefect.engine.results import PrefectResult
with Flow("my handled flow!", result=PrefectResult()):
...
Now when I run my flow, the PrefectResult.location contains the actual return value from my Task in it:
>>> state.result[first_result]._result.value
3
>>> state.result[first_result]._result.location
3
And this value 3 is also visible to Cloud users in the UI when inspecting the Task Run details:
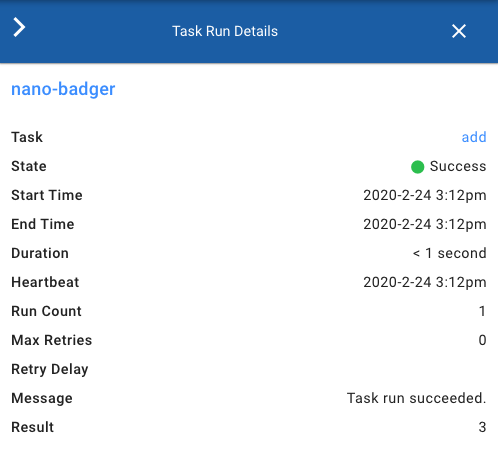
This is a useful backend for data that is small and safe to store in the database, as it requires no extra configuration.
# Migrating from Result Handlers
If you used result handlers in Prefect versions lower than 0.11.0, they have now been replaced by the Result subclasses described in this document.
If you use result handlers in your flows and upgrade to 0.11.0, they will be auto-converted at runtime into Result subclasses matching the storage backend -- for example GCSResultHandlers will turn into GCSResults.
Custom result handlers will be auto-converted at runtime into ResultHandlerResult classes, which act as a wrapper to expose the custom result handler's read and write methods.
As you write new flows or upgrade existing flows, consider using the new Result subclasses wherever you would have used result handlers. We do not have an official timeline for removing result handlers entirely, but they are currently in maintenance mode and new features leveraging dataflow in Prefect will be designed and implemented against the Result interface only going forward.