# Thinking Prefectly
This page will give you a gentle introduction to Prefect's core concepts. If you are keen to get started we have a Getting Started guide and ETL tutorial on building real-world data applications with Prefect.
Prefect is a tool for building data workflows. A workflow is a series of steps that are performed in a certain order.
In addition, Prefect allows you to specify more complex behaviors, like steps that pass information or data to other steps, steps that automatically retry when they encounter a problem, or steps that only run when previous steps fail.
Once the workflow has been defined, Prefect's engine executes it in a manner that respects all of the behaviors assigned to each step.
In this introduction, we'll cover the basics of defining tasks and combining those tasks into flows.
# Tasks
Prefect refers to each step as a task. In a simple sense, a task is nothing more than a Python function. In fact, the easiest way to create a new task is just by decorating an existing function. Let's make a simple task that prints "Hello, world!":
from prefect import task
@task
def say_hello():
print("Hello, world!")
Prefect has no restrictions on how much or how little each task can do. In general, we encourage "small tasks" over monolithic ones: each task should perform a discrete logical step of your workflow, but not more. This is because the Prefect engine does a lot of work to handle each task, including checkpointing the state after each task runs. Therefore, the more tasks you have, the more opportunities the engine has to be helpful. There's nothing wrong with "big tasks" - you could put your entire workflow in one giant task! - but the system as a whole will be less useful to you.
# Task inputs and outputs
Prefect tasks can optionally receive inputs and produce outputs. To take advantage of this feature, provide them in your task definition.
@task
def add(x, y=1):
return x + y
We could also enhance our "Hello, world!" task to say hello to a specific person:
@task
def say_hello(person: str) -> None:
print("Hello, {}!".format(person))
Type annotations
Notice how we used Python 3 annotations to tell Prefect our input and output types. This is completely optional, but the system may be able to enhance your workflow if you provide typing information.
# Task classes
Sometimes, you'll need to design classes that are more complex than a single function. For this, you can subclass the Prefect Task class and implement its __init__() and run() methods. Here's how our add task might look if we wanted it to have a customizable default:
from prefect import Task
class AddTask(Task):
def __init__(self, default: int, *args, **kwargs):
super().__init__(*args, **kwargs)
self.default = default
def run(self, x: int, y: int=None) -> int:
if y is None:
y = self.default
return x + y
# initialize the task instance
add = AddTask(default=1)
Notice subclassing a task is more powerful, but requires more explicit code. As demonstrated above, we must initialize the task instance in order to use it. When we used the @task decorator, it returned a task object that was already initialized.
# Flows
In Prefect, flows are used to describe the dependencies between tasks, such as their order or how they pass data around. If tasks are like functions, then you could think of a flow as a script that combines them in interesting ways.
# Functional API
The easiest way to build a flow is with Prefect's functional API. Create a flow as a context manager and call your tasks on each other as if they were regular functions. Prefect will track each function call and build up a computational graph that represents your workflow. Critically, no tasks are actually executed at this time.
Here is a flow that uses the add task we wrote earlier to add a few numbers together. Notice how tasks can accept numbers or even other tasks as inputs; Prefect automatically creates the appropriate connections (or "edges") in the flow graph. In addition, notice that we call add twice, generating two distinct copies of our task in the flow:
from prefect import Flow
with Flow("My first flow!") as flow:
first_result = add(1, y=2)
second_result = add(x=first_result, y=100)
# Running the flow
Once the flow has been created, we can execute it by calling flow.run(). In this case, the resulting State is Success, and we can also examine the State and result of each task:
state = flow.run()
assert state.is_successful()
first_task_state = state.result[first_result]
assert first_task_state.is_successful()
assert first_task_state.result == 3
second_task_state = state.result[second_result]
assert second_task_state.is_successful()
assert second_task_state.result == 103
The flow's run() method is a convenience function that handles some of the most important aspects of workflow management: scheduling, retries, data serialization, and more. If the flow has a schedule attached, calling flow.run() will sleep until the next scheduled time, run the flow, and sleep again until the next run.
Deferred execution
When you build a flow in Prefect, you're defining a computational graph that can be executed sometime in the future, possibly in a distributed environment. That's why most of this documentation follows a simple pattern: the flow is built (usually in a "with Flow():" context), and then the flow is run() as a second step. In production, you probably won't call flow.run() yourself, but rather let a management API handle execution.
# Parameters
Sometimes, it's useful to provide information to a flow at runtime. Prefect provides a special task called a Parameter for this purpose. Let's use a parameter to write a flow that says hello to someone:
from prefect import Parameter
with Flow("Say hi!") as flow:
name = Parameter("name")
say_hello(name)
If we run this flow, we'll see a variety of logs and also our print statement, as expected:
flow.run(name="Marvin")
# ... [logs]
# "Hello, Marvin!"
# ... [logs]
# Imperative API
The functional API makes it easy to define workflows in a script-like style. Sometimes, you may prefer to build flows in a more programmatic or explicit way. For this, we can use Prefect's imperative API.
flow = Flow("My imperative flow!")
# define some new tasks
name = Parameter("name")
second_add = add.copy()
# add our tasks to the flow
flow.add_task(add)
flow.add_task(second_add)
flow.add_task(say_hello)
# create non-data dependencies so that `say_hello` waits for `second_add` to finish.
say_hello.set_upstream(second_add, flow=flow)
# create data bindings
add.bind(x=1, y=2, flow=flow)
second_add.bind(x=add, y=100, flow=flow)
say_hello.bind(person=name, flow=flow)
This flow combines our addition tasks with the "say hello" task, using a state dependency (a non-data dependency) to specify that the "say hello" task shouldn't run until the second addition task is finished.
It's possible to create state-dependencies with Prefect's functional API, as well. When calling a task as if it was a function, pass a list of tasks to a special upstream_tasks keyword argument; Prefect will automatically call set_upstream() on each one.
Mix-and-match
You can switch between the functional API and the imperative API at any time. For example, half way through the previous code block, we could have called with flow: and entered a flow context in which the functional API was available. At a minimum, this would remove the need to pass flow=flow to each bind instruction. You can choose whichever style you prefer.
# Orchestrating flows
Prefect's Core Python API is a powerful tool to describe task dependencies and even to run flows right from your Python shell, notebook, or a long-running Python script. However, you can also leverage a ready-to-use state database and UI backend that already works perfectly to orchestrate any of your Prefect flows and make monitoring and orchestration easy.
Prefect Core ships with an open source, lightweight version of our highly-available, production-ready backend product Prefect Cloud.
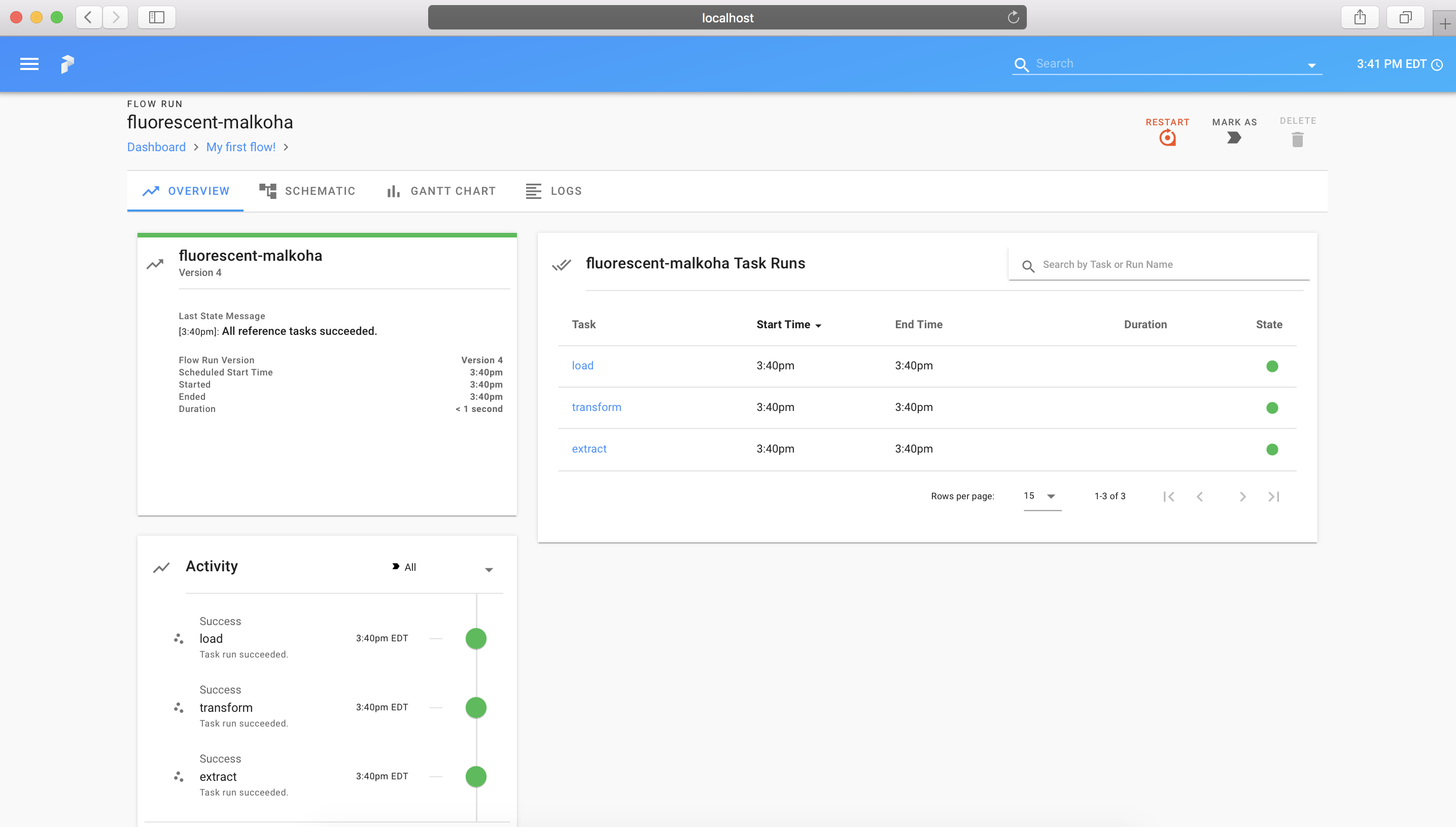
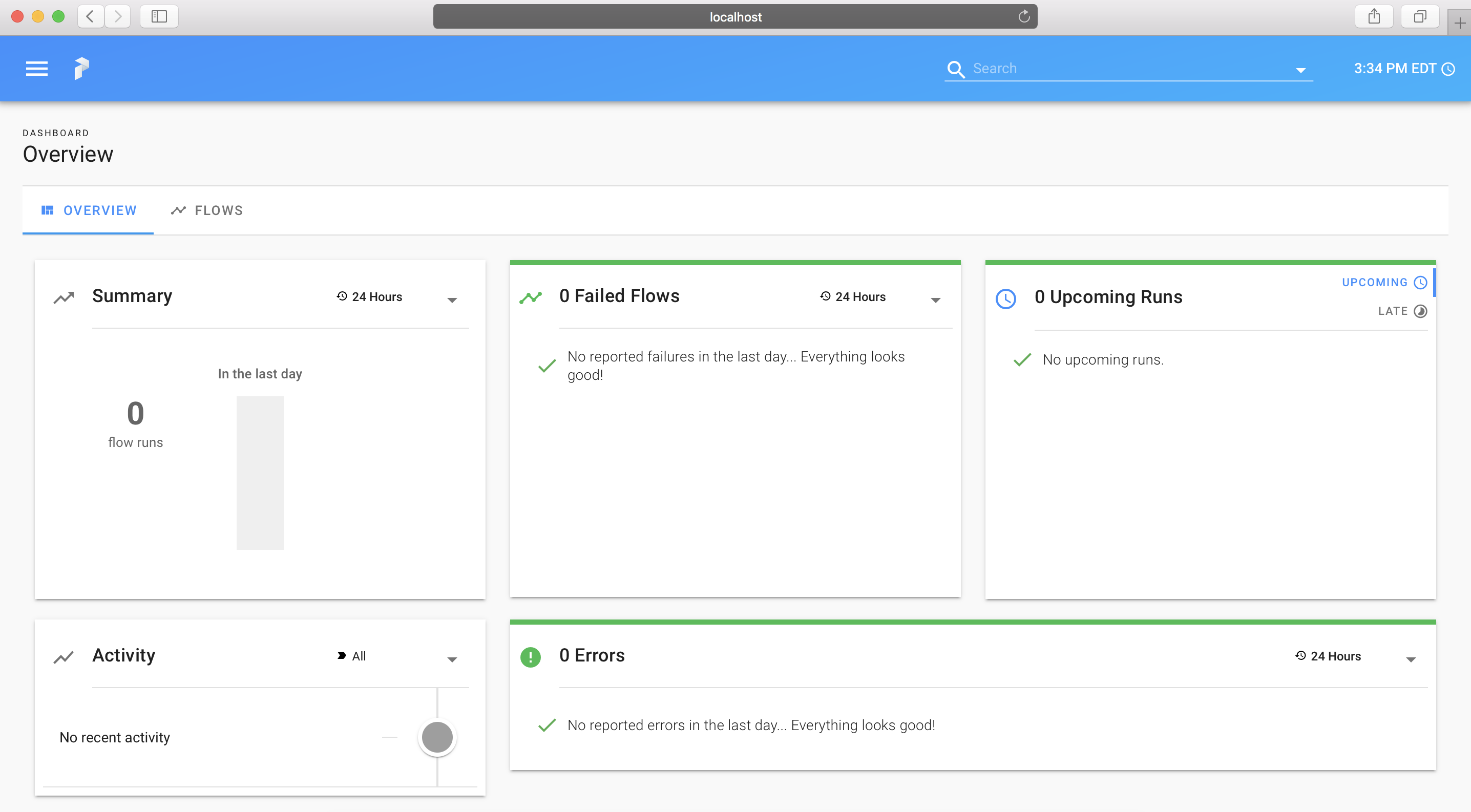
Let's take a very quick look into what a flow orchestrated with Prefect Core's server looks like; for more information, see the documentation on Orchestration.
After starting and configuring Core's server, navigate to http://localhost:8080 to see the Prefect UI:
Backend configuration
Before registering your flow with your local backend make sure you have called prefect backend server from the CLI to configure Prefect for local orchestration.
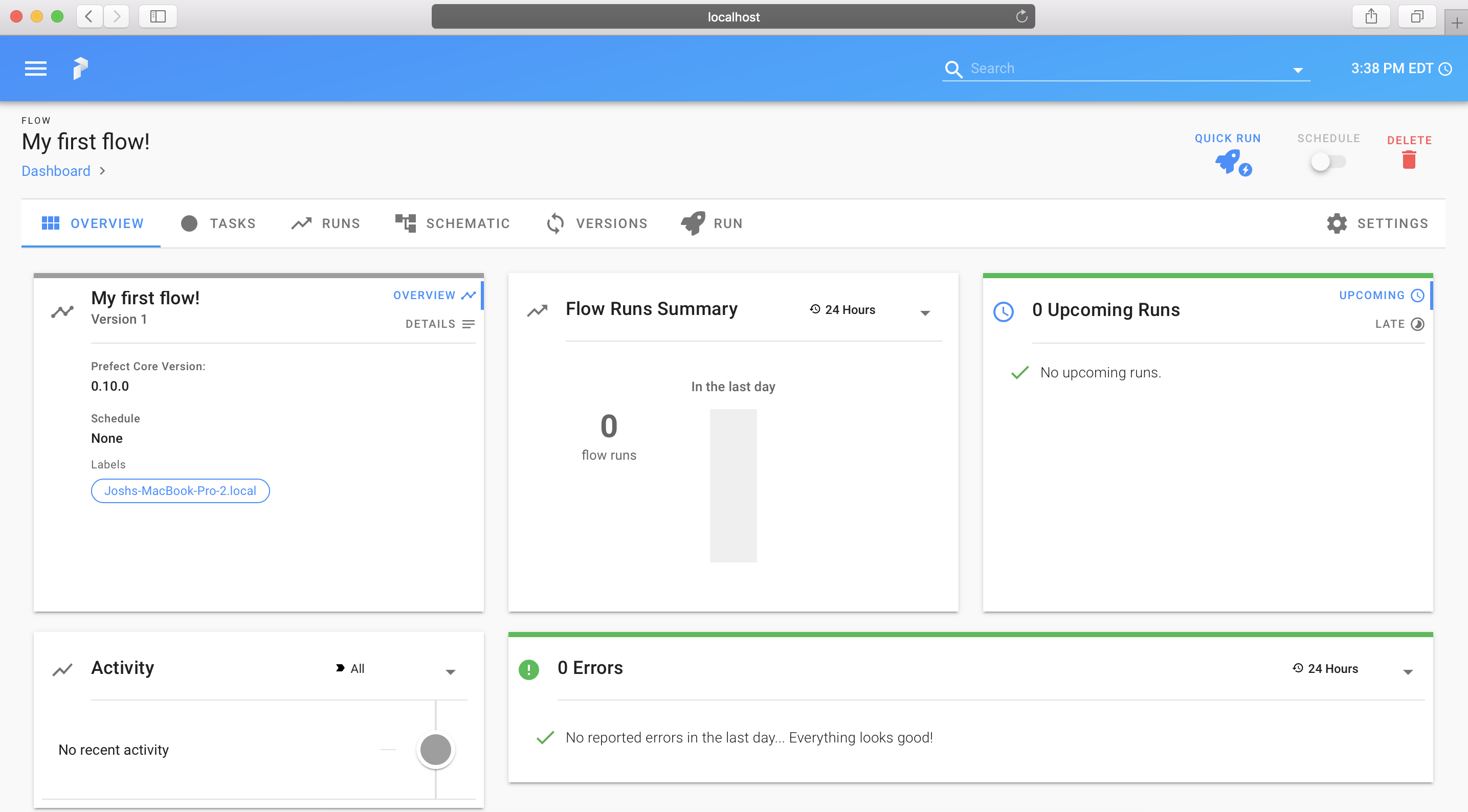
Register any of your flows; they will register with your local backend:
>>> flow.register()
Flow: http://localhost:8080/flow/796f7ad4-26c8-4e5d-bab1-dc687691da88
You can use the URL returned from the register() call to navigate directly to the flow in your Prefect server's UI:
Start a local agent that can communicate between the server and your flow code.
prefect agent local start
And then trigger your flow from the UI using the "Run" button! You will see the agent pick up your work:
[2020-03-28 19:40:49,985] INFO - agent | Found 1 flow run(s) to submit for execution.
[2020-03-28 19:40:50,021] INFO - agent | Deploying flow run 86f3c550-34d4-4f1a-945b-803eb20ca36f
And the UI will be updated with the state of the flow run: