

# ETL with Prefect
In this tutorial, we'll use Prefect to improve the overall structure of the ETL workflow from the previous tutorial.
Follow along in the Terminal
cd examples/tutorial
python 02_etl_flow.py
# It's E, T, L, not ETL
Prefect's smallest unit of work is a Python function; so our first order of business is to rework our example into functions.
The first question that may come to mind is "how large/small should a function be?". An easy approach would be to split the work up into explicit "extract", "transform", and "load" functions, like so:
def extract(...):
# fetch all aircraft and reference data
...
return all_data
def transform(all_data):
# clean the live data
...
def load(all_data):
# save all transformed data and reference data to the database
...
This would be functional, however, it still does not address some of the problems from the original code base:
- What happens to already-fetched reference data if pulling live data fails?
- What happens to the already-transformed data if the database is not available?
These points highlight the fact that extract() and load() are still arbitrarily scoped. This brings us to a rule of thumb when deciding how large to make each function: look at the input and output data that the workflow needs at each step. In our case the reference data and live data come from different sources and are stored separately. Lets refactor a bit more, taking this new insight into consideration:
def extract_reference_data(...):
# fetch reference data
...
return reference_data
def extract_live_data(...):
# fetch live data
...
return live_data
def transform(live_data, reference_data):
# clean the live data
...
return transformed_data
def load_reference_data(reference_data):
# save reference data to the database
...
def load_live_data(transformed_data):
# save transformed live data to the database
...
# Leveraging Prefect
Now that we have appropriately sized functions and an idea of how these functions relate to one another, let's encapsulate our workflow with Prefect.
# First step
Decorate any function that Prefect should run with prefect.task:
from prefect import task, Flow
@task
def extract_reference_data(...):
# fetch reference data
...
return reference_data
@task
def extract_live_data(...):
# fetch live data
...
return live_data
@task
def transform(live_data, reference_data):
# clean the live data
...
return transformed_data
@task
def load_reference_data(reference_data):
# save reference data to the database
...
@task
def load_live_data(transformed_data):
# save transformed live data to the database
...
# Second step
Specify data and task dependencies within a prefect.Flow context:
# ...task definitions above
with Flow("Aircraft-ETL") as flow:
reference_data = extract_reference_data()
live_data = extract_live_data()
transformed_live_data = transform(live_data, reference_data)
load_reference_data(reference_data)
load_live_data(transformed_live_data)
Note: none of the tasks are actually executed at this time, as the with Flow(...): context manager allows Prefect to reason about dependencies between tasks and build an execution graph that will be executed later. In this case, the execution graph would look like so:
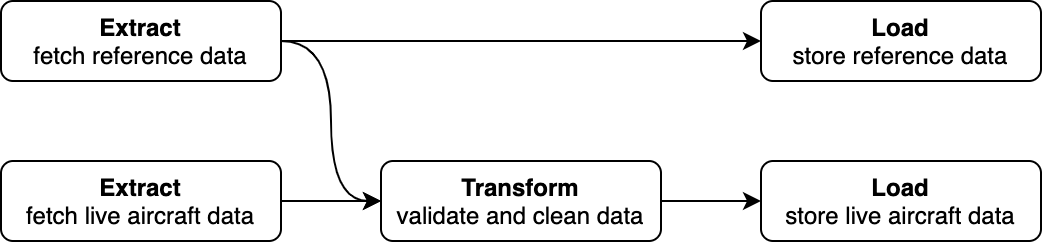
A huge improvement over our original implementation!
# Third step
Execute the Flow!
# ...flow definition above
flow.run()
At this point, the Tasks (our Python functions) are executed in the appropriate order, with data being passed from task-to-task as specified in the execution graph.
Prefect Task Library
Prefect provides a Task Library that includes common Task implementations and integrations with Kubernetes, GitHub, Slack, Docker, AWS, GCP, and more!
Up Next!
Let's parameterize our Flow to make it more reusable.