

# Flow Configuration
So far we've been using the default flow configuration. When using a Prefect Backend, each flow is configured with:
Storage: describes where the flow should be stored to and loaded from during execution. By default this uses Local storage, which stores your flow locally as a file on your machine.
Run Configuration: describes where and how a flow run should be executed. By default this is a UniversalRun, which works with any Agent.
Executor: describes where and how tasks in a flow run should be executed. By default this is a LocalExecutor, which executes tasks serially in a single thread.
To demonstrate these, we'll add two more requirements to our hello-flow:
- The greeting used should be provided by an environment variable
GREETING - We need to be able to greet lots of people in parallel
# Configure Environment Variables
We'll handle the environment variable requirement first. Environment variables in a flow run can be configured in several places. Two common locations:
On the agent, by passing
--env KEY=VALUEwhen starting the agent. All flows run by the agent will then have that environment variable set.On the flow, through the flow's RunConfig. All runs of the flow will then have that environment variable set.
Here we'll use a LocalRun, since we're running a local agent.
Our new flow code might look like this:
import os
import prefect
from prefect import task, Flow, Parameter
from prefect.run_configs import LocalRun
@task
def say_hello(name):
# Load the greeting to use from an environment variable
greeting = os.environ.get("GREETING")
logger = prefect.context.get("logger")
logger.info(f"{greeting}, {name}!")
with Flow("hello-flow") as flow:
people = Parameter("people", default=["Arthur", "Ford", "Marvin"])
say_hello.map(people)
# Configure the `GREETING` environment variable for this flow
flow.run_config = LocalRun(env={"GREETING": "Hello"})
# Register the flow under the "tutorial" project
flow.register(project_name="tutorial")
Try registering and running the above flow - you should see that the GREETING
environment variable is properly forwarded and used.
Changing or configuring a flow's run_config is a useful way to customize the
environment in which a flow runs. There are different types for deploying on
different platforms (KubernetesRun for kubernetes, DockerRun for docker,
...), each with different options. See the run configuration
docs for more information.
# Enable Parallel Execution
Sometimes flows can benefit from parallel execution. This is especially useful when combined with mapped tasks, where there are lots of opportunities for parallelism.
The simplest way to enable parallel execution for a flow is to swap out the default LocalExecutor for a LocalDaskExecutor. This will run your tasks in parallel using a pool of threads (or processes).
Since our say_hello task runs far too quickly to benefit from parallel
execution, we'll add a time.sleep to provide a better demo.
import os
import time
import prefect
from prefect import task, Flow, Parameter
from prefect.run_configs import LocalRun
from prefect.executors import LocalDaskExecutor
@task
def say_hello(name):
# Add a sleep to simulate some long-running task
time.sleep(10)
# Load the greeting to use from an environment variable
greeting = os.environ.get("GREETING")
logger = prefect.context.get("logger")
logger.info(f"{greeting}, {name}!")
with Flow("hello-flow") as flow:
people = Parameter("people", default=["Arthur", "Ford", "Marvin"])
say_hello.map(people)
# Configure the `GREETING` environment variable for this flow
flow.run_config = LocalRun(env={"GREETING": "Hello"})
# Use a `LocalDaskExecutor` to run this flow
# This will run tasks in a thread pool, allowing for parallel execution
flow.executor = LocalDaskExecutor()
# Register the flow under the "tutorial" project
flow.register(project_name="tutorial")
Register and run the flow.
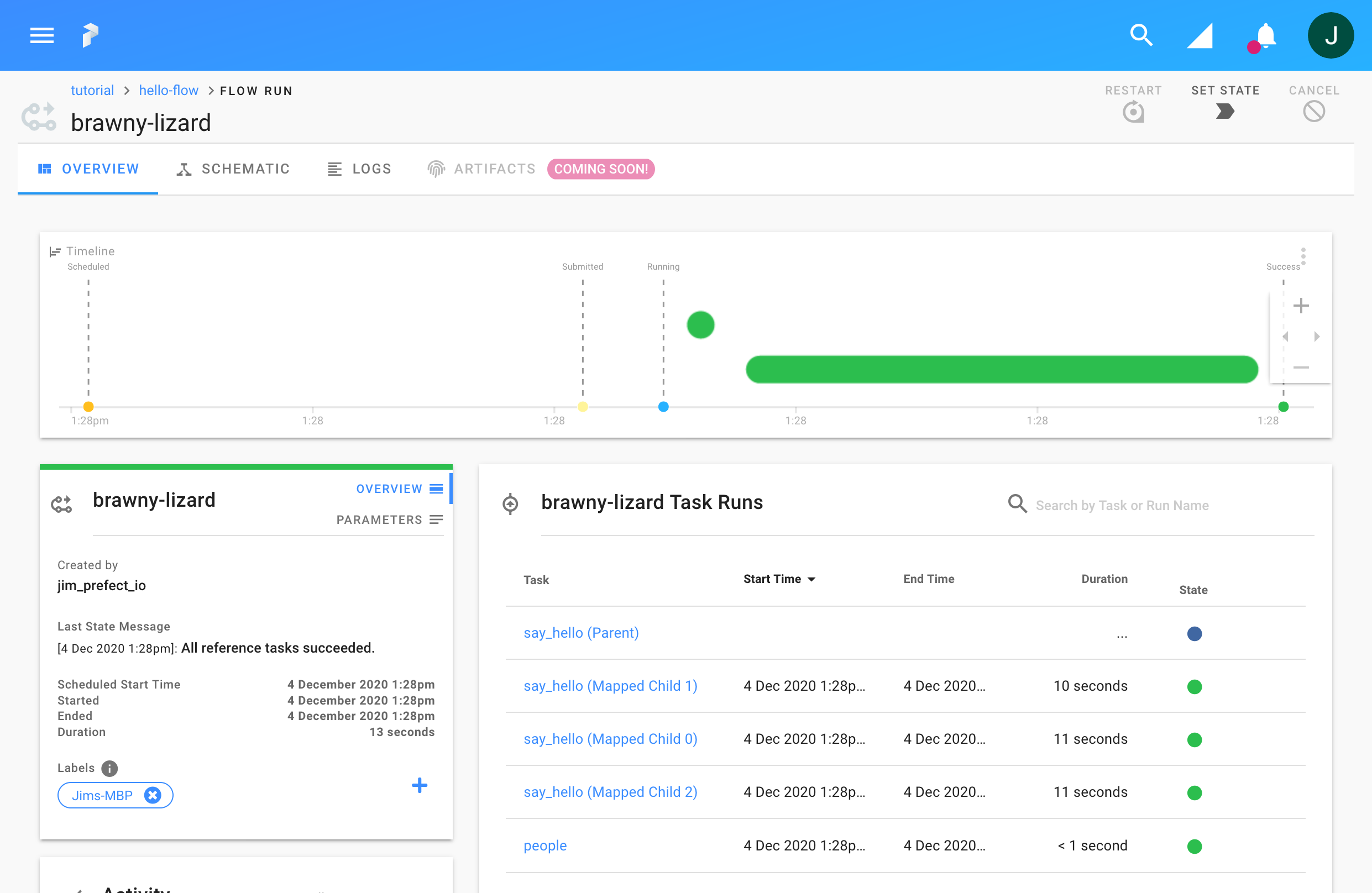
You should see multiple say_hello tasks running in parallel, providing a
noticeable speedup (this ran in 13 seconds, when serially it would have taken
30 seconds). If you look through the logs you can also see logs from each task
interleaved, showing they ran concurrently.
Not every flow will require or benefit from parallelism, but when needed swapping out the executor can result in large performance improvements. Prefect supports several executors not discussed here, for more information see the executors documentation.